Ultra high density spectral characteristic extraction, comparison
Pronunciation Requirement Reference
Under viewing with high density spectral data, human pronunciation is found to be made up from slices of various components in groups.
Those slices of components shared the same direction of changes with similar power. After linking them with corresponding changes in sound,
we can connect them with various muscular movements that happened during pronunciation.
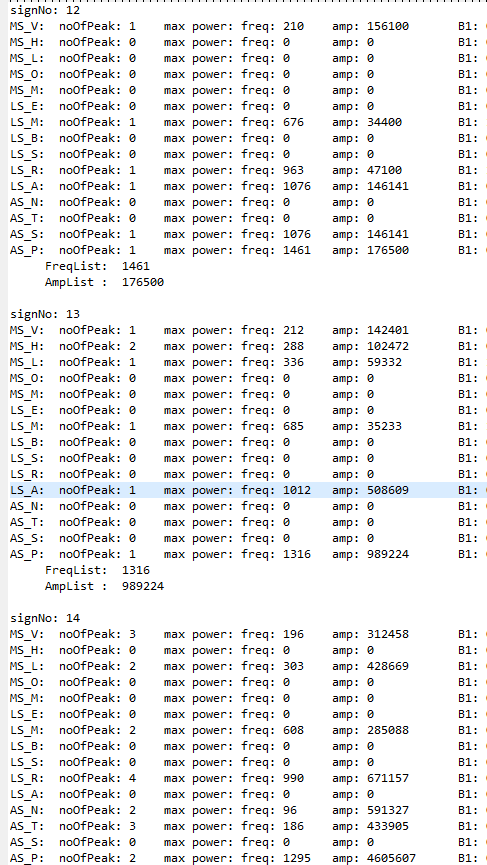
Muscular Movement listings
Those formed a new fundamental element in pronunciation analysis, and filled the missing trace on the slightest change audible with human ear.
In short, any difference in human pronunciation can be represented using this analysis system, with corresponding muscular activities in detail.
Example of usage on /t/
For example, utilizing the power of detail sound analysis, we are able to characterize even short changes,
which is a signature pattern of consonants(10~20ms). If /t/ phoneme is pronounced at the start of a word,
there are already several combinations of muscular movement which can indicate the speaker’s emotion, muscular habit,
skillfulness of the word.
Breakthrough in analysis
Limited by the conventional analysis technology, those are nearly omitted in sound analysis.
Even missing those data, we can still use macro pattern in sound, doing the word recognition with current “AI” technology.
However, this cannot be used on micro patterns, it is basically the information resolution issue.