Generic Check for AI Voices!
The Background
There are many AI synthesis technologies, even within a provider. This induced various types of synthesized sound in the world.
From the oldest technology using cut and paste only to the latest one using neural network (AI) to build sound with segments in around 0.1s.
There is a global need of having a generic way to identify those audio from real human speech.
In fields application involved cyber security, user authentication, fake news filtering and anti-scam.

common breaking edge along purple dotted line
3D model of the AI synthesized sounds
Common Pattern in AI Voice?
With our unique technology in ultra high density spectral characteristics, we noticed common patterns from synthesized sound which
only last for around 10ms which are unable to be observed using conventional technologies. As using conventional technologies,
characteristics are found in segments around 0.1s, summing up with other signals, those signature patterns would only contribute ~10% shift
in power, making it to be unnoticeable
What makes those patterns?
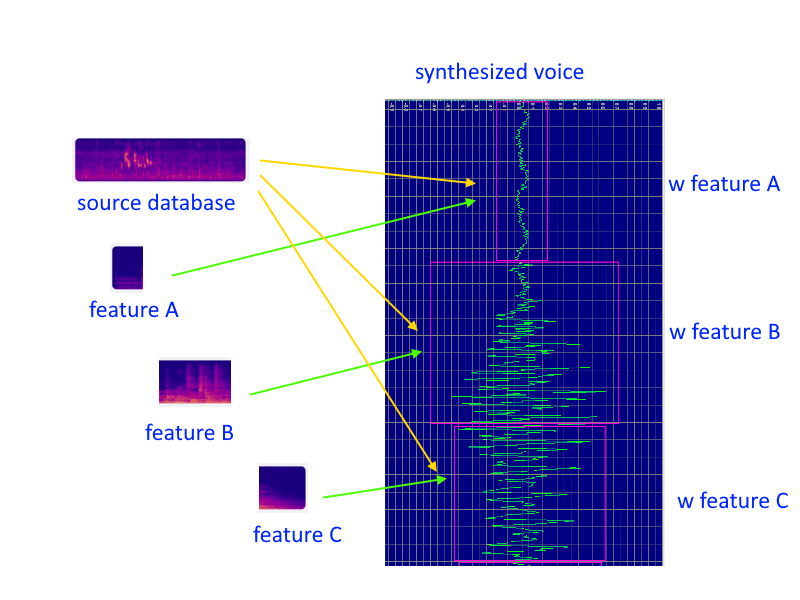
These patterns are created under the current sound synthesis process. Conventionally sounds are handled segment by segment.
Being the basic unit of any process, segments are being analyzed, classified, mixing and adding features, finally being merged one by one.
Hence if there are always merging points between two adjacent segments. Those formed the “common patterns” within every synthesized sound.
Why this detection is better than others?
Compared to other “macro patterns” claimed to be on synthesized sound, the merging pattern between segments are common even from
those made by previous generations of sound synthesized technology. Hence making the detection using this technology generic over
all known synthesized sounds.