Ultra high density spectral characteristic extraction, comparison
Orange is the audio waveform; Green is FFT, Red is the high density spectral data
Got Extra detail
Under viewing with high density spectral data, human pronunciation is found to be made up from slices of various components in groups.
Making use of this characteristic, we can have a high effective filtering of noise, and feature extraction with patterns in high density.
The 3D plot of a sound with the extra detail in RED, conventional data in GREEN, and Audio signal in ORANGE, we can zoom in as 3D object viewer in detail
Comparative to the sensitivity of human beings
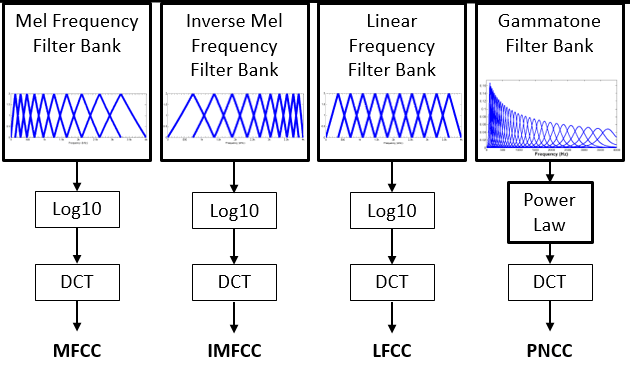
In the characteristic extraction, there are already a bundle of processes and tools developed with conventional technology(MFCC, etc).
With a great increase in the information density, those tools and processes are inappropriate.
To maximize the efficiency in characterizing and comparing, we merged the muscular information we know,
and forged the spatial data into another characteristic spec based on muscular activities.
More suitable for pronunciation analysis
Other than about the detail level, changing the point of view to the muscular movement would also conserve the pronunciation as a
collection of muscular movement, rather than a sound pattern alone. This would help push Linguistics to achieve a subjective representation
in pronunciation. So we can characterize a pronunciation as how a person controls their muscles to make the sound. All comparison,
correctness, reproducing the sound would done without affecting by the vocal chod quality (which is acting as the dominant component
currently due to its high power contribution)
Isolating the changes
With the characteristic tool ready, we are able to do the analysis on accents, muscular status.
Interestingly, the components corresponding to the vocal cord vary a lot with age, gender, and health status.
Those components on lip/oral cavity control muscles would be similar and stable among all human beings.
By isolating the vocal cord component, we are still able to recognize the word spoken,
enabling us to identify the speaker and word spoken even with a sore throat.